Data Lineage
Why Would You Use Lineage?
Data lineage is used to capture data dependencies within an organization. It allows you to track the inputs from which a data asset is derived, along with the data assets that depend on it downstream.
For more information about data lineage, refer to About DataHub Lineage.
Goal Of This Guide
This guide will show you how to
- Add lineage between datasets.
- Add column-level lineage between datasets.
- Read lineage.
Prerequisites
For this tutorial, you need to deploy DataHub Quickstart and ingest sample data. For detailed steps, please refer to Datahub Quickstart Guide.
Before adding lineage, you need to ensure the targeted dataset is already present in your datahub. If you attempt to manipulate entities that do not exist, your operation will fail. In this guide, we will be using data from sample ingestion.
Add Lineage
- GraphQL
- Curl
- Python
mutation updateLineage {
updateLineage(
input: {
edgesToAdd: [
{
downstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)"
upstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"
}
]
edgesToRemove: []
}
)
}
Note that you can create a list of edges. For example, if you want to assign multiple upstream entities to a downstream entity, you can do the following.
mutation updateLineage {
updateLineage(
input: {
edgesToAdd: [
{
downstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)"
upstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"
}
{
downstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)"
upstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"
}
]
edgesToRemove: []
}
)
}
For more information about the updateLineage mutation, please refer to updateLineage.
If you see the following response, the operation was successful:
{
"data": {
"updateLineage": true
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' --data-raw '{ "query": "mutation updateLineage { updateLineage( input:{ edgesToAdd : { downstreamUrn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\", upstreamUrn : \"urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)\"}, edgesToRemove :{downstreamUrn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\",upstreamUrn : \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\" } })}", "variables":{}}'
Expected Response:
{ "data": { "updateLineage": true }, "extensions": {} }
# Inlined from /metadata-ingestion/examples/library/lineage_emitter_rest.py
import datahub.emitter.mce_builder as builder
from datahub.emitter.rest_emitter import DatahubRestEmitter
# Construct a lineage object.
lineage_mce = builder.make_lineage_mce(
[
builder.make_dataset_urn("hive", "fct_users_deleted"), # Upstream
],
builder.make_dataset_urn("hive", "logging_events"), # Downstream
)
# Create an emitter to the GMS REST API.
emitter = DatahubRestEmitter("http://localhost:8080")
# Emit metadata!
emitter.emit_mce(lineage_mce)
Expected Outcome
You can now see the lineage between fct_users_deleted and logging_events.
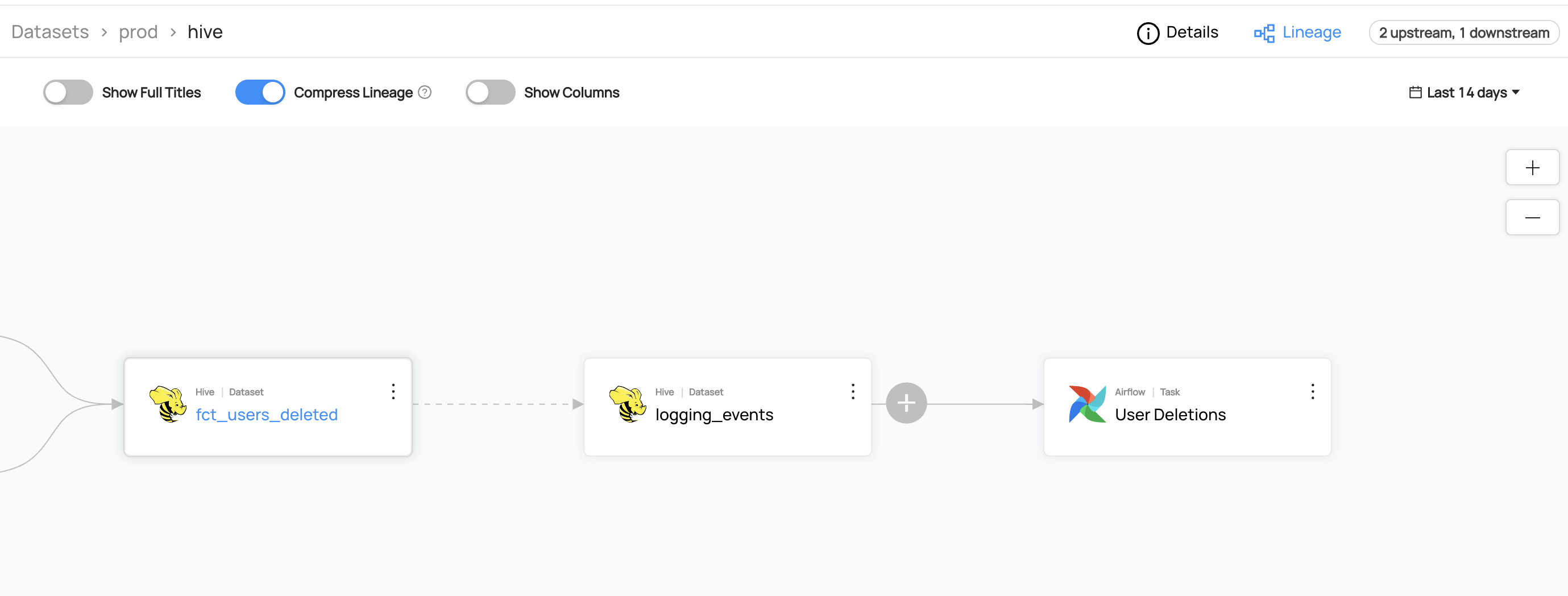
Add Column-level Lineage
- Python
# Inlined from /metadata-ingestion/examples/library/lineage_emitter_dataset_finegrained_sample.py
import datahub.emitter.mce_builder as builder
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
from datahub.metadata.com.linkedin.pegasus2avro.dataset import (
DatasetLineageType,
FineGrainedLineage,
FineGrainedLineageDownstreamType,
FineGrainedLineageUpstreamType,
Upstream,
UpstreamLineage,
)
def datasetUrn(tbl):
return builder.make_dataset_urn("hive", tbl)
def fldUrn(tbl, fld):
return builder.make_schema_field_urn(datasetUrn(tbl), fld)
fineGrainedLineages = [
FineGrainedLineage(
upstreamType=FineGrainedLineageUpstreamType.FIELD_SET,
upstreams=[
fldUrn("fct_users_deleted", "browser_id"),
fldUrn("fct_users_created", "user_id"),
],
downstreamType=FineGrainedLineageDownstreamType.FIELD,
downstreams=[fldUrn("logging_events", "browser")],
),
]
# this is just to check if any conflicts with existing Upstream, particularly the DownstreamOf relationship
upstream = Upstream(
dataset=datasetUrn("fct_users_deleted"), type=DatasetLineageType.TRANSFORMED
)
fieldLineages = UpstreamLineage(
upstreams=[upstream], fineGrainedLineages=fineGrainedLineages
)
lineageMcp = MetadataChangeProposalWrapper(
entityUrn=datasetUrn("logging_events"),
aspect=fieldLineages,
)
# Create an emitter to the GMS REST API.
emitter = DatahubRestEmitter("http://localhost:8080")
# Emit metadata!
emitter.emit_mcp(lineageMcp)
Expected Outcome
You can now see the column-level lineage between datasets. Note that you have to enable Show Columns to be able to see the column-level lineage.
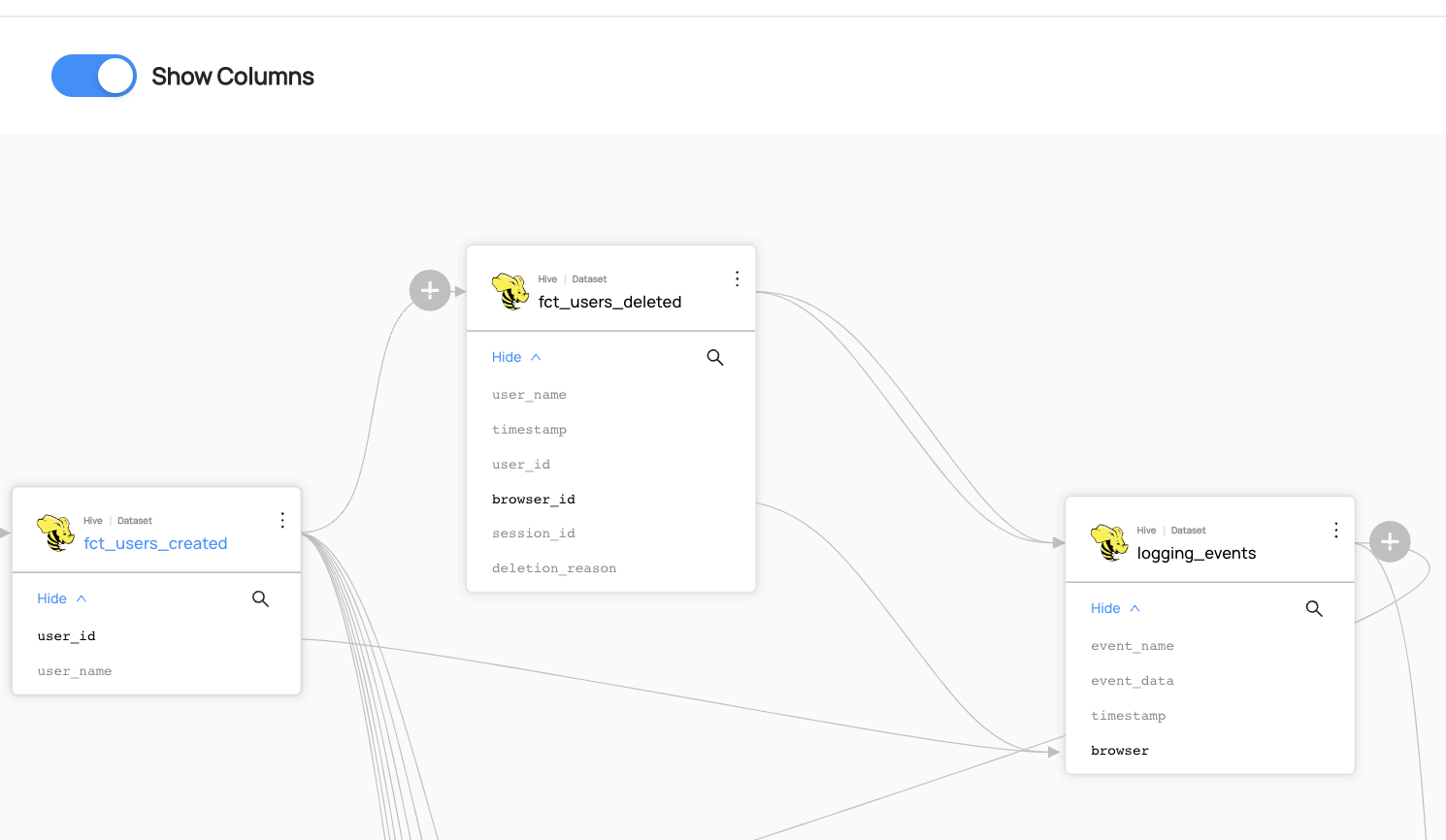
Add Lineage to Non-Dataset Entities
You can also add lineage to non-dataset entities, such as DataJobs, Charts, and Dashboards. Please refer to the following examples.
| Connection | Examples | A.K.A |
|---|---|---|
| DataJob to DataFlow | - lineage_job_dataflow.py | |
| DataJob to Dataset | - lineage_dataset_job_dataset.py | Pipeline Lineage |
| Chart to Dashboard | - lineage_chart_dashboard.py | |
| Chart to Dataset | - lineage_dataset_chart.py |
Read Lineage (Lineage Impact Analysis)
- GraphQL
- Curl
- Python
query scrollAcrossLineage {
scrollAcrossLineage(
input: {
query: "*"
urn: "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)"
count: 10
direction: DOWNSTREAM
orFilters: [
{
and: [
{
condition: EQUAL
negated: false
field: "degree"
values: ["1", "2", "3+"]
}
]
}
]
}
) {
searchResults {
degree
entity {
urn
type
}
}
}
}
Note that degree means the number of hops in the lineage. For example, degree: 1 means the immediate downstream entities, degree: 2 means the entities that are two hops away, and so on.
The GraphQL example shows using lineage degrees as a filter, but additional search filters can be included here as well.
This will perform a multi-hop lineage search on the urn specified. For more information about the scrollAcrossLineage mutation, please refer to scrollAcrossLineage.
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' --data-raw '{ { "query": "query scrollAcrossLineage { scrollAcrossLineage( input: { query: \"*\" urn: \"urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)\" count: 10 direction: DOWNSTREAM orFilters: [ { and: [ { condition: EQUAL negated: false field: \"degree\" values: [\"1\", \"2\", \"3+\"] } ] } ] } ) { searchResults { degree entity { urn type } } }}"
}}'
# Inlined from /metadata-ingestion/examples/library/read_lineage_execute_graphql.py
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
# Query multiple aspects from entity
query = """
query scrollAcrossLineage($input: ScrollAcrossLineageInput!) {
scrollAcrossLineage(input: $input) {
searchResults {
degree
entity {
urn
type
}
}
}
}
"""
variables = {
"input": {
"query": "*",
"urn": "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)",
"count": 10,
"direction": "DOWNSTREAM",
"orFilters": [
{
"and": [
{
"condition": "EQUAL",
"negated": "false",
"field": "degree",
"values": ["1", "2", "3+"],
}
]
}
],
}
}
result = graph.execute_graphql(query=query, variables=variables)
print(result)
The Python SDK example shows how to read lineage of a dataset. Please note that the aspect_type parameter can vary depending on the entity type.
Below is a few examples of aspect_type for different entities.
| Entity | Aspect_type | Reference |
|---|---|---|
| Dataset | UpstreamLineageClass | Link |
| Datajob | DataJobInputOutputClass | Link |
| Dashboard | DashboardInfoClass | Link |
| DataFlow | DataFlowInfoClass | Link |
Learn more about lineages of different entities in the Add Lineage to Non-Dataset Entities Section.
Expected Outcome
As an outcome, you should see the downstream entities of logging_events.
{
"data": {
"scrollAcrossLineage": {
"searchResults": [
{
"degree": 1,
"entity": {
"urn": "urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_123)",
"type": "DATA_JOB"
}
},
...
{
"degree": 2,
"entity": {
"urn": "urn:li:mlPrimaryKey:(user_analytics,user_name)",
"type": "MLPRIMARY_KEY"
}
}
]
}
},
"extensions": {}
}
Read Column-level Lineage
You can also read column-level lineage via Python SDK.
- Python
# Inlined from /metadata-ingestion/examples/library/read_lineage_dataset_rest.py
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import UpstreamLineageClass
# Get the current lineage for a dataset
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
urn = "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)"
result = graph.get_aspect(entity_urn=urn, aspect_type=UpstreamLineageClass)
print(result)
Expected Outcome
As a response, you will get the full lineage information like this.
{
"UpstreamLineageClass": {
"upstreams": [
{
"UpstreamClass": {
"auditStamp": {
"AuditStampClass": {
"time": 0,
"actor": "urn:li:corpuser:unknown",
"impersonator": null,
"message": null
}
},
"created": null,
"dataset": "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)",
"type": "TRANSFORMED",
"properties": null,
"query": null
}
}
],
"fineGrainedLineages": [
{
"FineGrainedLineageClass": {
"upstreamType": "FIELD_SET",
"upstreams": [
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD),browser_id)",
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD),user_id)"
],
"downstreamType": "FIELD",
"downstreams": [
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD),browser)"
],
"transformOperation": null,
"confidenceScore": 1.0,
"query": null
}
}
]
}
}